Skip to content
Projects
Groups
Snippets
Help
Loading...
Help
Submit feedback
Contribute to GitLab
Sign in
Toggle navigation
W
webmagic
Project
Project
Details
Activity
Releases
Cycle Analytics
Repository
Repository
Files
Commits
Branches
Tags
Contributors
Graph
Compare
Charts
Issues
0
Issues
0
List
Board
Labels
Milestones
Merge Requests
0
Merge Requests
0
CI / CD
CI / CD
Pipelines
Jobs
Schedules
Charts
Wiki
Wiki
Snippets
Snippets
Members
Members
Collapse sidebar
Close sidebar
Activity
Graph
Charts
Create a new issue
Jobs
Commits
Issue Boards
Open sidebar
沈俊林
webmagic
Commits
9a0a4051
Commit
9a0a4051
authored
Apr 04, 2014
by
yihua.huang
Browse files
Options
Browse Files
Download
Email Patches
Plain Diff
[doc] ch3 part1
parent
7ca644cd
Changes
1
Hide whitespace changes
Inline
Side-by-side
Showing
1 changed file
with
53 additions
and
4 deletions
+53
-4
user-manual-new.md
zh_docs/user-manual-new.md
+53
-4
No files found.
zh_docs/user-manual-new.md
View file @
9a0a4051
...
...
@@ -5,7 +5,7 @@ WebMagic是一个简单灵活、便于二次开发的爬虫框架。除了可以
你可以直接使用WebMagic进行爬虫开发,也可以定制WebMagic以适应复杂项目的需要。
## 1. 使用WebMagic
## 1.
在项目中
使用WebMagic
WebMagic主要包含两个jar包:
`webmagic-core-{version}.jar`
和
`webmagic-extension-{version}.jar`
。在项目中添加这两个包的依赖,即可使用WebMagic。
...
...
@@ -88,6 +88,8 @@ public class GithubRepoPageProcessor implements PageProcessor {
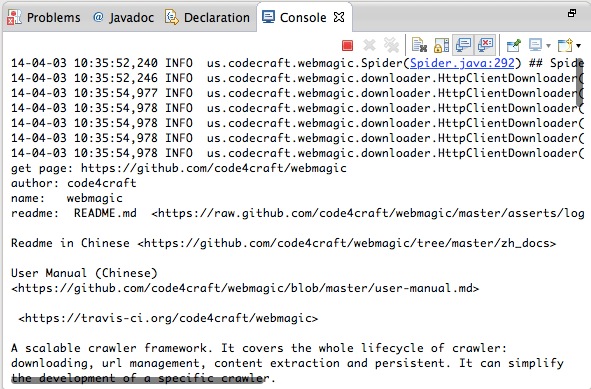
<div
style=
"page-break-after:always"
></div>
## 2.下载和编译源码
WebMagic是一个纯Java项目,如果你熟悉Maven,那么下载并编译源码是非常简单的。如果不熟悉Maven也没关系,这部分会介绍如何在Eclipse里导入这个项目。
...
...
@@ -158,11 +160,58 @@ Intellij Idea默认自带Maven支持,import项目时选择Maven项目即可。
## 3. 基本的爬虫
### 3.1 抽取内容(xpath, regex, css selector, jsonpath)
## 3. 基本的爬虫
### 3.1 实现PageProcessor
在WebMagic里,实现一个基本的爬虫只需要编写一个类,实现
`PageProcessor`
接口。这个类包含了抓取一个网站所需要的所有定制化信息。以之前的
`GithubRepoPageProcessor`
为例:
```
java
public
class
GithubRepoPageProcessor
implements
PageProcessor
{
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private
Site
site
=
Site
.
me
().
setRetryTimes
(
3
).
setSleepTime
(
1000
);
@Override
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public
void
process
(
Page
page
)
{
// 以下部分定义了如何抽取页面信息,并保存下来
page
.
putField
(
"author"
,
page
.
getUrl
().
regex
(
"https://github\\.com/(\\w+)/.*"
).
toString
());
page
.
putField
(
"name"
,
page
.
getHtml
().
xpath
(
"//h1[@class='entry-title public']/strong/a/text()"
).
toString
());
if
(
page
.
getResultItems
().
get
(
"name"
)
==
null
)
{
//skip this page
page
.
setSkip
(
true
);
}
page
.
putField
(
"readme"
,
page
.
getHtml
().
xpath
(
"//div[@id='readme']/tidyText()"
));
// 这一步从页面发现后续的url地址来抓取
page
.
addTargetRequests
(
page
.
getHtml
().
links
().
regex
(
"(https://github\\.com/\\w+/\\w+)"
).
all
());
}
@Override
public
Site
getSite
()
{
return
site
;
}
public
static
void
main
(
String
[]
args
)
{
Spider
.
create
(
new
GithubRepoPageProcessor
())
//从"https://github.com/code4craft"开始抓
.
addUrl
(
"https://github.com/code4craft"
)
//开启5个线程抓取
.
thread
(
5
)
//启动爬虫
.
run
();
}
}
```
### 3.2 抽取内容(xpath, regex, css selector, jsonpath)
### 3.
2
发现链接
### 3.
3
发现链接
### 3.
3
处理多个页面
### 3.
4
处理多个页面
## 4. 使用注解
...
...
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment